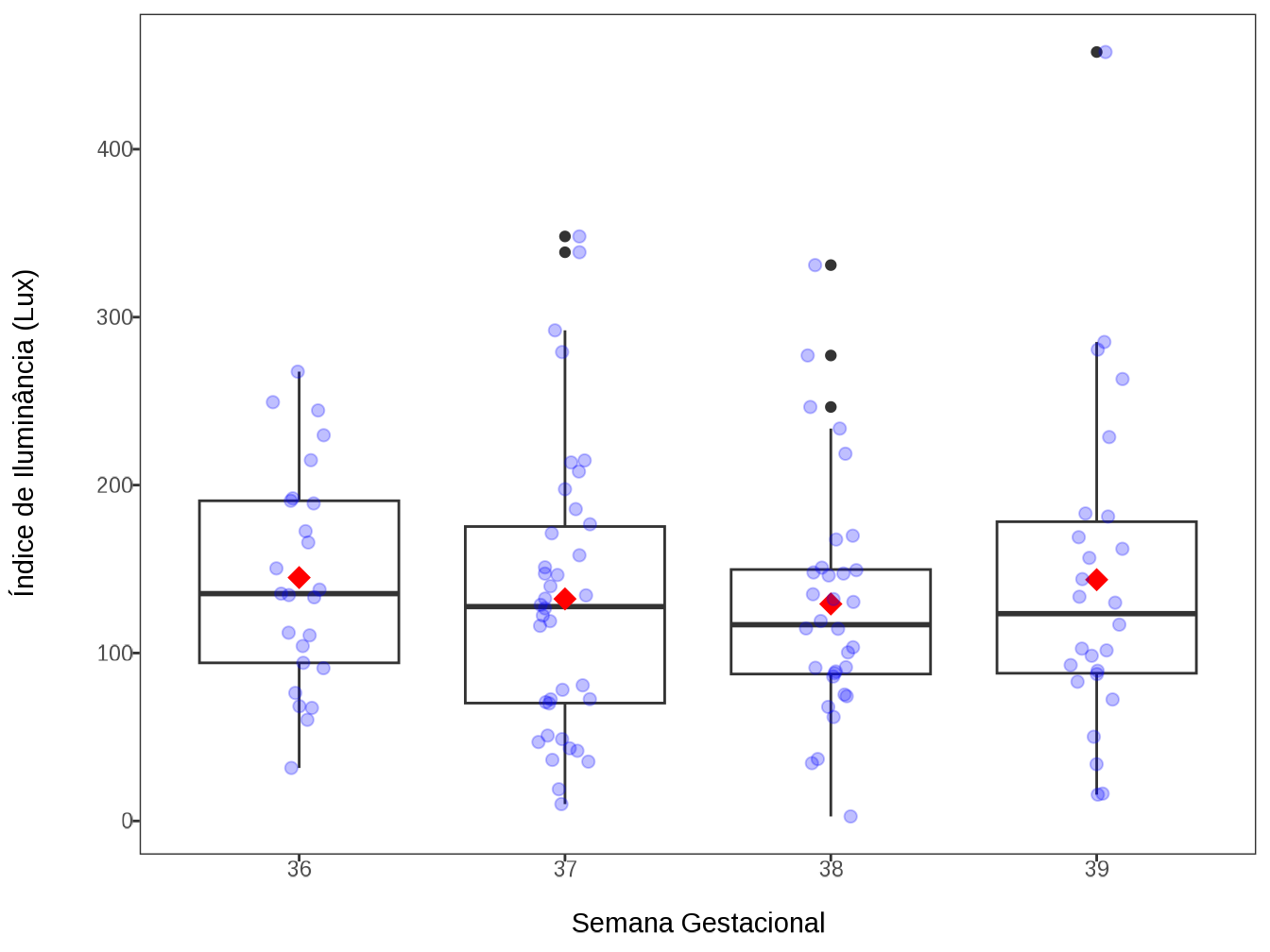
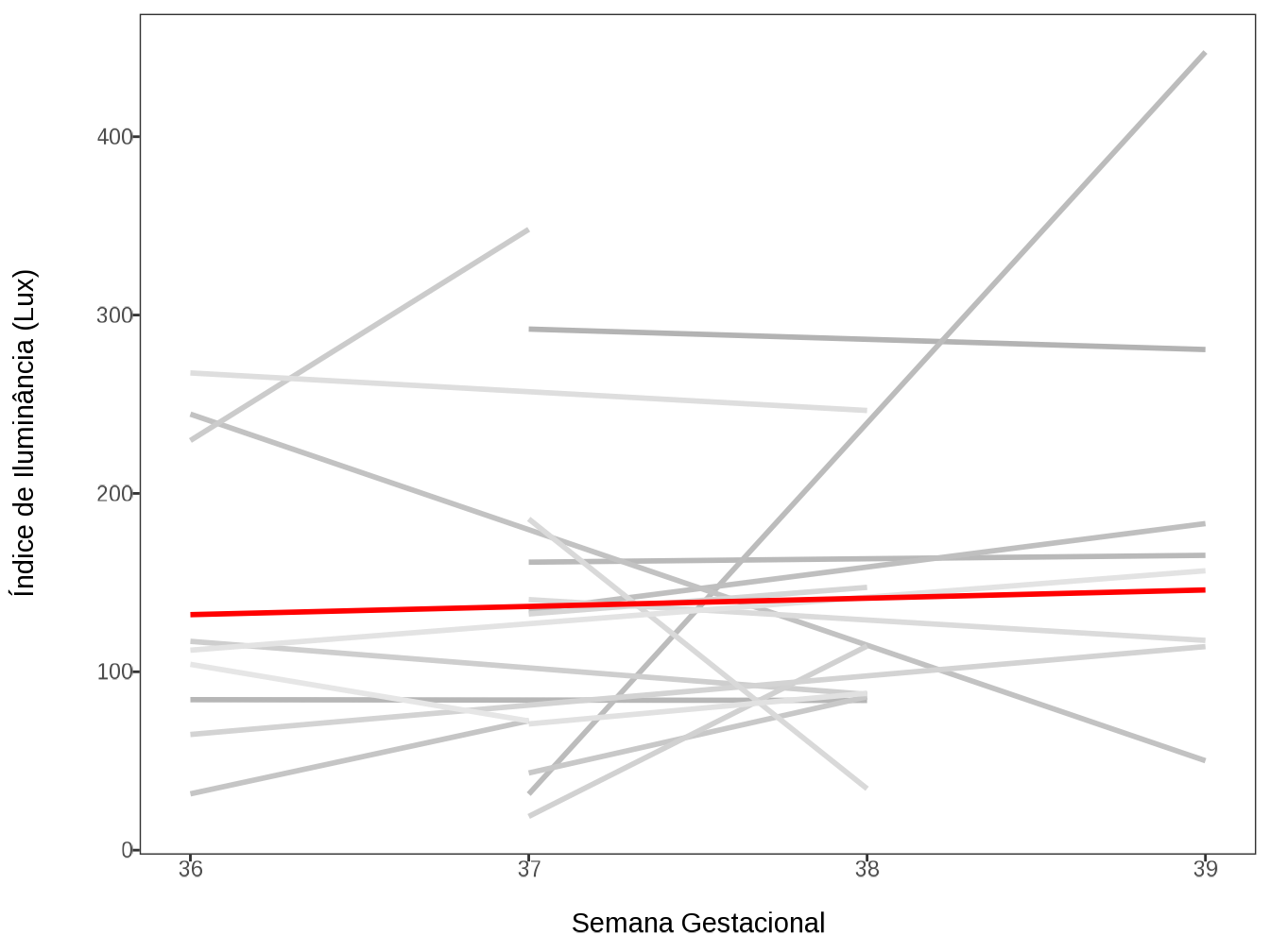
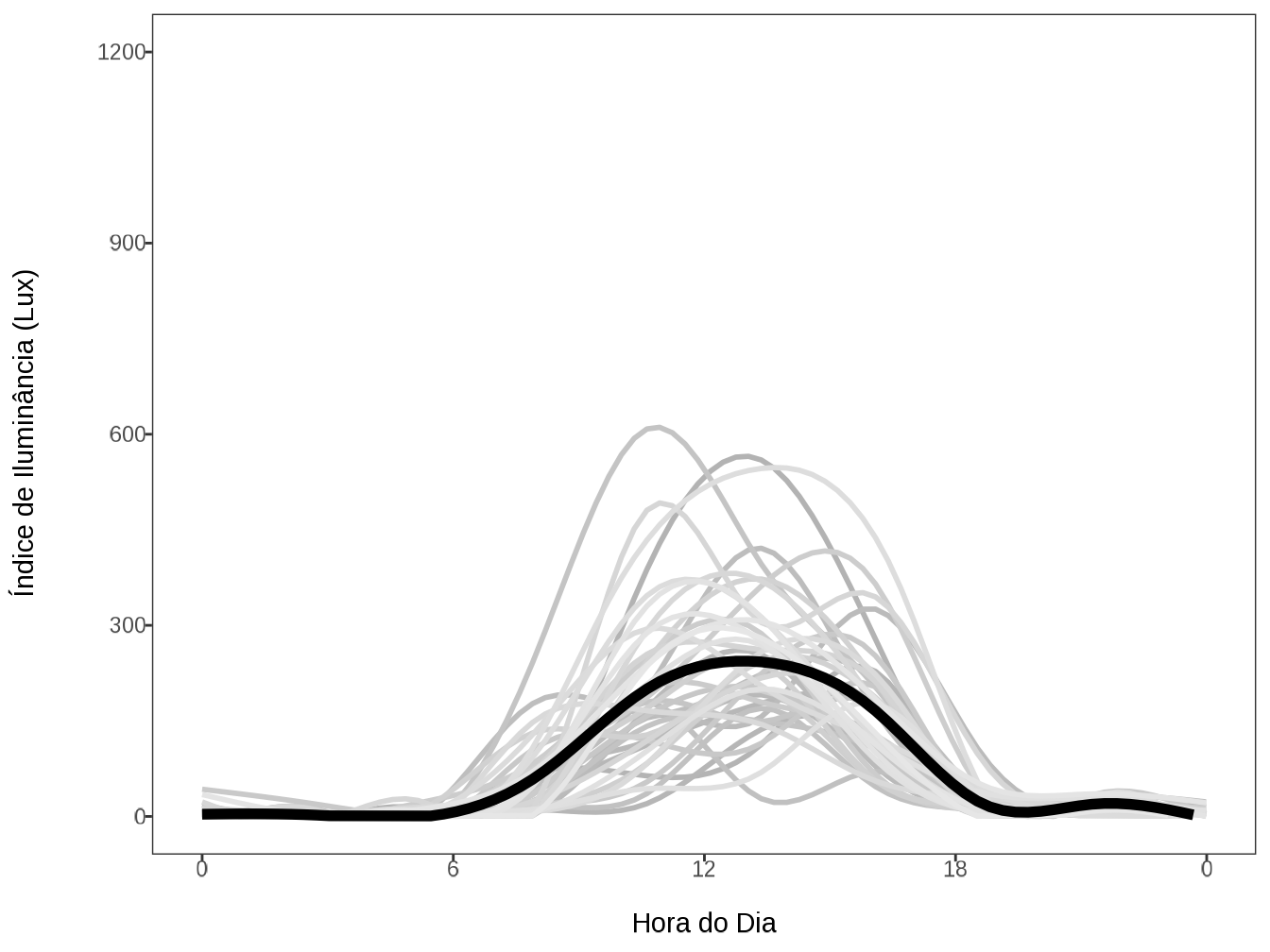
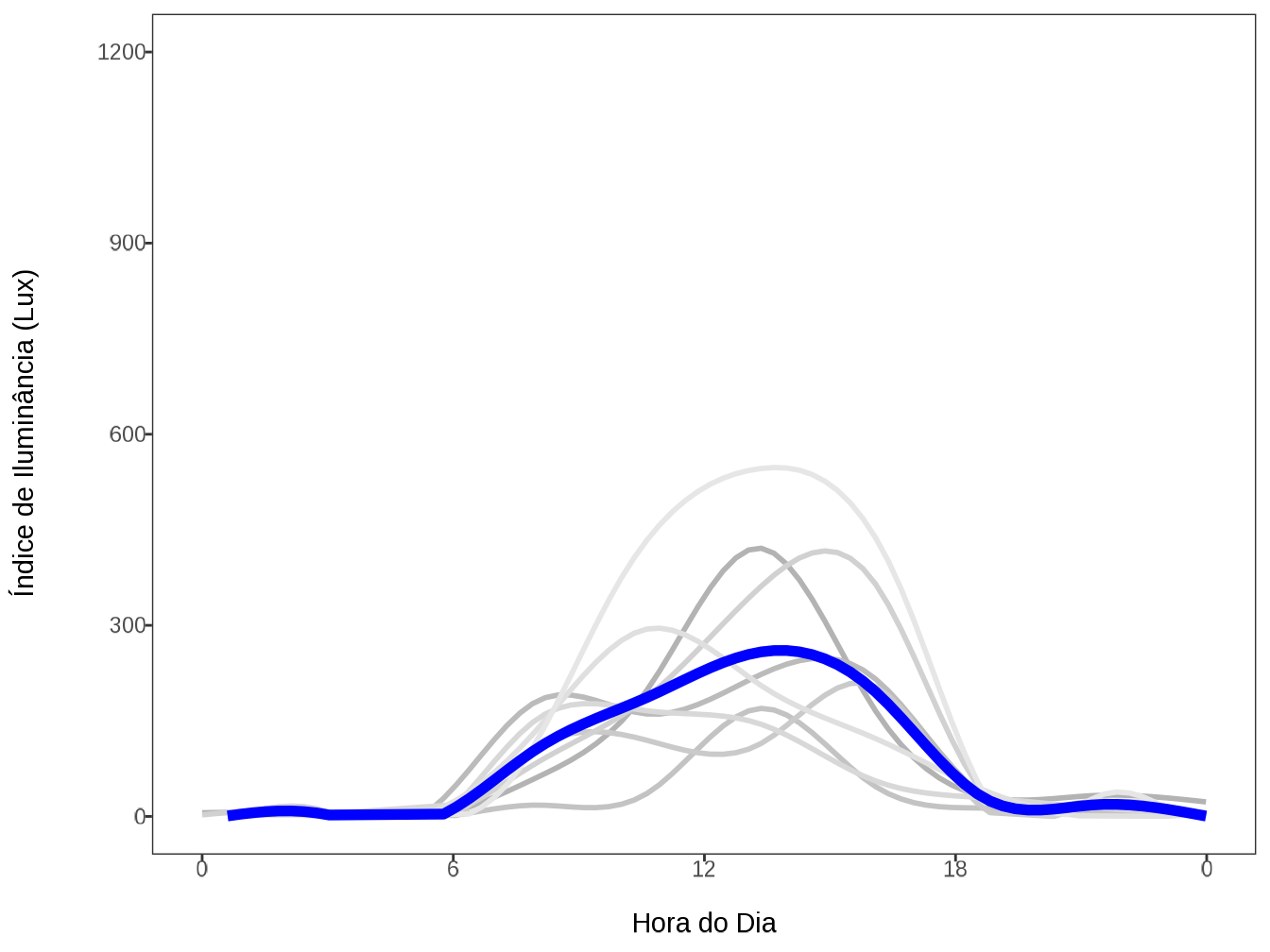
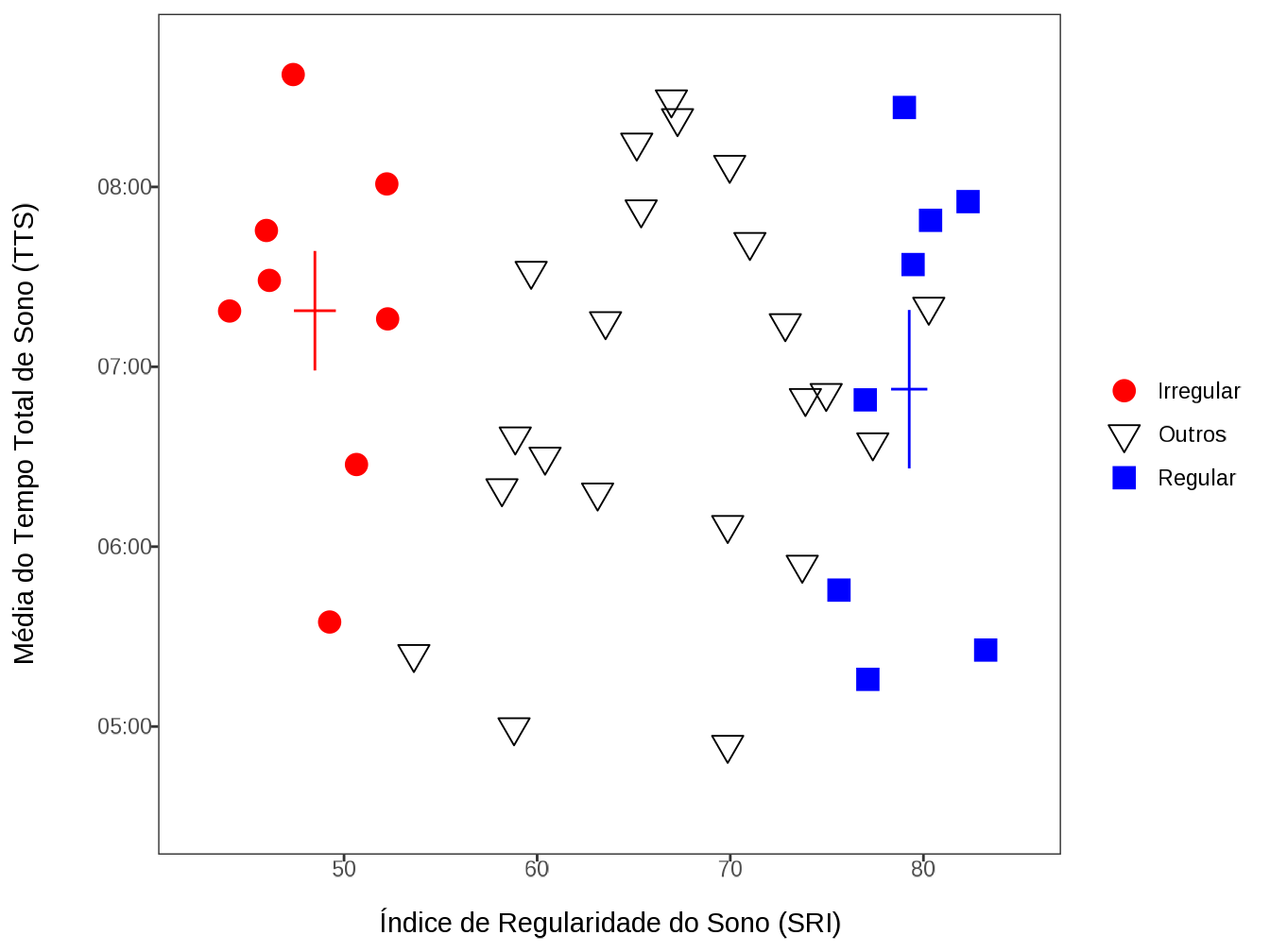
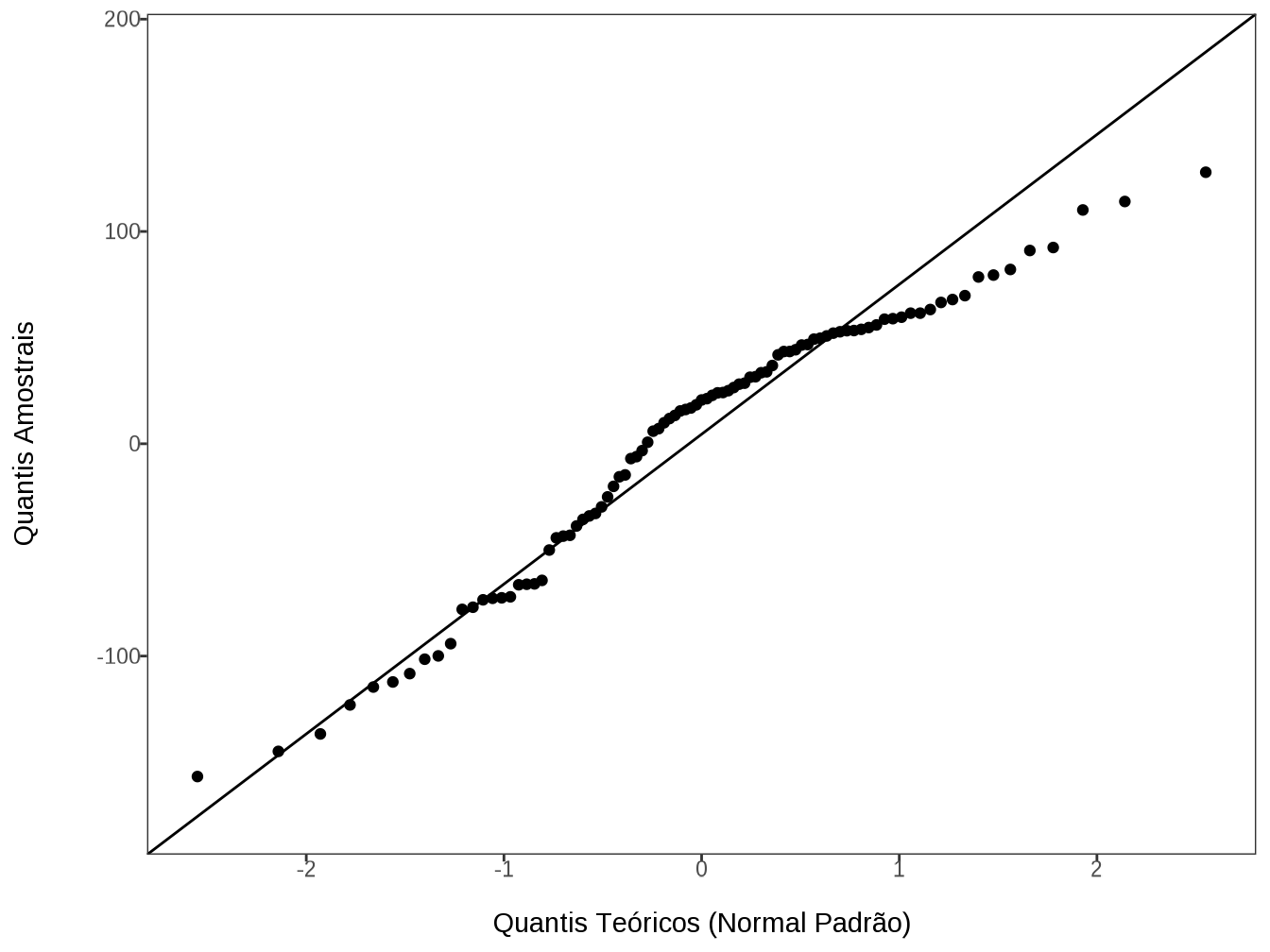
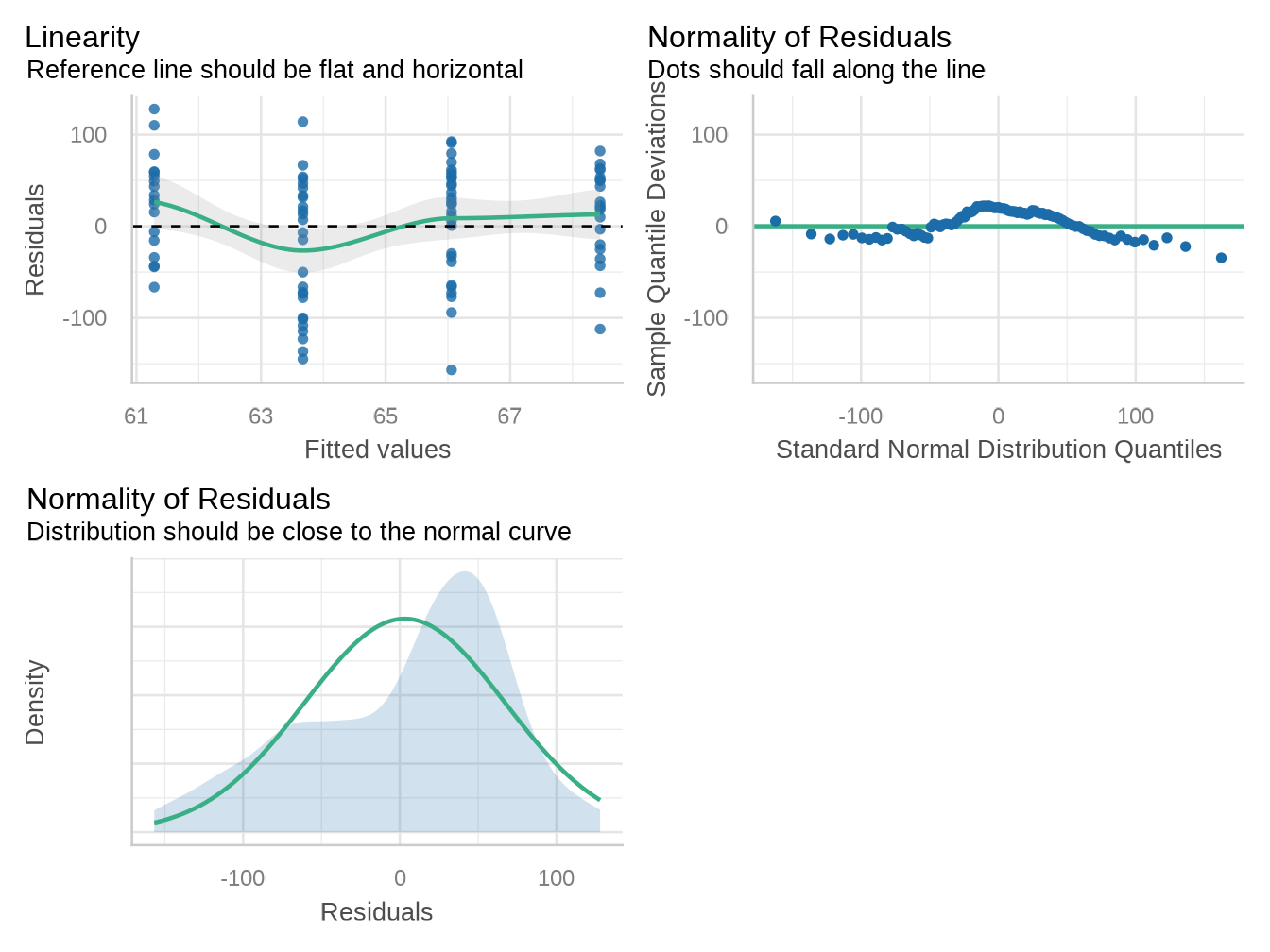
field_form_data |> glimpse()
#> Rows: 74
#> Columns: 20
#> $ id <chr> "9e858cd8", "a053ce64", "b37bd425", "db850249", "022…
#> $ timestamp <dttm> 2023-05-21 11:18:49, 2023-05-26 17:55:52, 2023-06-3…
#> $ birth_date <date> 1991-03-22, 2001-07-25, 1989-02-23, 1998-01-12, 199…
#> $ age <dbl> 32.16388889, 21.83611111, 34.35277778, 25.47222222, …
#> $ weight_before <dbl> 70, 50, 87, 70, 64, 84, 49, 60, 75, 66, 64, 72, 92, …
#> $ weight_current <dbl> 86, 75, 94, 76, 78, 87, 58, 91, 89, 79, 76, 89, 110,…
#> $ height <dbl> 160, 156, 174, 169, 153, 168, 157, 164, 164, 159, 16…
#> $ bmi_before <dbl> 27.34375000, 20.54569362, 28.73563218, 24.50894577, …
#> $ bmi_current <dbl> 33.59375000, 30.81854043, 31.04769454, 26.60971255, …
#> $ family_income <dbl> 4000, 2800, 6000, 5000, 3000, 4000, 3000, 9000, 6000…
#> $ gestations <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 1…
#> $ study <lgl> FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALS…
#> $ work <lgl> TRUE, TRUE, TRUE, TRUE, FALSE, TRUE, TRUE, FALSE, TR…
#> $ health_plan <lgl> FALSE, FALSE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE…
#> $ solo <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FAL…
#> $ ethnicity <ord> Branca, Parda, Branca, Branca, Parda, Parda, Branca,…
#> $ exercise <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
#> $ education <ord> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
#> $ deliveries <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0…
#> $ abortions <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0…